This is a three-part article whose aim is to serve as an update to my work on the personal research portal, as long as to explain yet another practical example of a PLE, something that many found useful at the PLE Conference as a means to embody theoretical ramblings.
The first part deals with infrastructures and how my PLE is built in the sense of which applications shape it. The second one deals with the information management workflow. The third one puts the personal learning environment in relationship with the university.
Mainstreaming your PLE
If in The Workings of a Personal Learning Environment (I): the infrastructure we saw how a PLE could be built, we here explain how can it work. Or, in other words, how the information flows through it and is fixed and transformed.
An observation, though, should be made about the substance and the form of the PLE which, actually, can be translated into two conditions (necessary, not sufficient) for a PLE to be useful to oneself (not talking here about it being “successful” as measured by third parties). If we understand useful as that it serves our purposes in learning more and better, or doing more research and better, then:
- Setting up a PLE means that you really want to learn or do research, and that you’re willing to confront what this means. This basically zeroes in performing the processes of analysis, synthesis, abstraction and critique. That is: read, note, think and write. Many people think that PLEs require a lot of reading or writing. Wrong: it is learning that does.
- Setting up a PLE means that you just built a parallel structure to your usual pencil and paper procedures. Maintaining two channels requires extra work. The more you mainstream and focus in just one platform, the better. I myself found my PLE useful once it became mainstream in the production of my knowledge and network. With rare exceptions (and reducing), everything is on my PLE.
Reading
I would like to make a point before going on with the discussion. While I argue that open publishing (and your PLE fits in this category) should be part of a scholar’s commandments (especially if in a publicly founded university or research centre), I acknowledge that the idea of where to publish (e.g. paper vs. blog) is at least debatable. But concerning reading, I have instead a very strong opinion: RSS feeds let you reach more information and in an easier way. Thus, I have serious doubts whether a knowledge worker can be up-to-date in their discipline and/or be efficient in their information management without the help of an RSS feed reader.
Now, being a scholar, reading is a total priority, even if it sometimes will imply me lagging behind deadlines in other kind of tasks. Of course there are different categories in the things I read, but besides the ones that are strictly personal, reading usually goes first place. So, first things in the morning are e-mail, feed reader and Twitter (some tags and users come in by through the feed reader too) until the morning reading is done or almost done.
The first exercise is to tell things that have to be read “right now” from things that are going to be saved for later. Amongst these, some will be printed or saved in the mp3/mp4 player for the train, or for a quiet moment, and some others will be shifted to the future. In any case, the key thing to do is to read the important things or at least to know what I’ve got pending reading of interest.
Storing
If what I find to be really important, I at least read the abstract+introduction+conclusions and save it on a folder on my hard drive. This is a folder labelled with the main topic (e.g. e-readiness) under a general “readings” folder. This is useful afterwards when writing: you can make Acrobat perform a full text search for a keyword in a whole folder. You don’t have to remind everything: just know you read something about that and that it has to be “somewhere” in those folders.
If the article is read thoroughly, it will go to the bibliographic manager and sometimes even to the blog with a comment or a reflection.
Sometimes what gets to me is not an article, or the article has some extra information worth keeping apart. In that case, the wiki plays its part. For instance, the last edition of Leonard Waverman’s Connectivity Scorecard will be included in my bibliography. Nevertheless, because the datasets have now been made public online, a Connectivity Scorecard entry will be created in the wiki. This is laborious and makes little sense in the short run. In the long run, your list of ICT Indices and ICT Data sources is always up-to-date, you can easily list all the works you’ve read by Leonard Waverman or Kaylan Dasgupta or under the category of e-Readiness or tagged with connectivity scorecard. In the long run, the effort pays back, it far does.
Once you think you’ve more or less scanned a topic, posted about it and created the necessary references, then you can forget about them: you know they’ll be on your blog with the reflections you got at that time and the interlinked references with other works, comments, authors, etc.
I gather information on a double basis:
- things I know 100% I’ll be using, e.g. the World Economic Forum’s Global Information Technology Report 2009-2010, a reference in the field of e-Readiness and digital development.
- things I might use somewhen: politics 2.0, for instance, or e-government. Not sure whether I’ll be using them, but likely, as it normally ends up happening. e.g. Last year I wrote a book chapter on Spanish Politics 2.0. During a year and a half I had een gathering info on that topic “just in case” and storing it in my hard drive, putting the main references in the bibliography and saving the rest “for later”. I knew, when I got the proposal to write the chapter, that whatever I got it had to be there. There was a lot of crap, but enough good references to prepare a fair chapter. “Just in case” also works pretty much well to update syllabuses or to prepare non-academic conferences, as they are full of facts and good examples.
What about delicious? I normally use it just for (a) news or (b) applied practices/examples. In other words: information with expiry-dates or that interest me just to build lists. Delicious is useful for me to quickly share resources that need low elaboration.
So, summing up:
- If I find something that seems really relevant, I scan it and store it the best way possible.
- If I you find something that is just probably relevant, I store it under a “tag” in the hard drive and in a way I can later perform brute force searches without crashing my computer (this procedure is diminishing along time and being substituted by the former one and trashing leftovers).
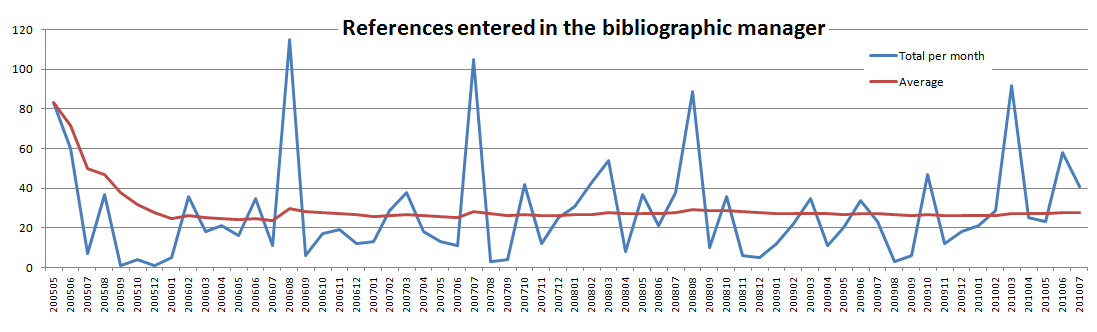
The following chart plots the references entered in the bibliographic manager since it went online (May 2005). Simple as it is, it shows two things: the first one is that despite some irregularities, the average has always been around the 27 new entries per month, which implies how mainstreamed the tool is with my daily work; the second one is that, besides the long-term regular pace, some months are “better” than others and can be easily identified as (a) periods of preparation of papers/speeches and (b) holidays, often used to “catch up” with pending readings.
Sharing
Some of the sharing can be inferred from the storing, as the whole PLE is open (with just a very very few exceptions).
If we follow the information management timeline, some interesting news are shared through Twitter, either directly (using retweets or bit.ly) or indirectly: my Google Shared account directly sends everything to Twitter and everything that goes to delicious is made public at the moment.
As can be seen in the image image in The Workings of a Personal Learning Environment (I): the infrastructure, the lifestream or aggregator and FriendFeed collect all the activity from the several applications and services I use (blogs, updates to the wiki and the bibliographic manager, Slideshare, Youtube… not Prezi), being the main difference that FriendFeed gathers “social” information (Facebook, Linkedin, Dopplr) that the aggregator does not.
Talking of which: I still have to find a return for Dopplr and Google Calendar. I think they give a sense of presence (of “realness”) worth keeping. Besides, Google Calendar holds right now three calendars: one gathers the public events I attend; a second one is my teaching schedule (more about this in the third part: The Workings of a Personal Learning Environment: the institutional fit); the third one is the ICT4D Calendar, a collaborative project and an easy way to keep track of ICT4D conferences while also letting others know about them. I’m pretty sure the latter is the most important as, within its limited success, it is a good trial on decentralized collaboration.
Keep reading: The Workings of a Personal Learning Environment (III): the institutional fit.
